红酒数据集建立决策树
在数据分析和机器学习中,Wine(红酒)数据集是一个经典的数据集,用于分类问题。这个数据集包含了三个不同来源的意大利葡萄酒的化学分析结果。我们将使用 Python 中的一些常见工具来导入这个数据集。
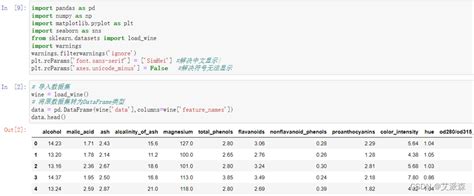
步骤 1: 导入必要的库
```python
import numpy as np
import pandas as pd
from sklearn.datasets import load_wine
```
步骤 2: 加载数据集
```python
加载 Wine 数据集
wine_data = load_wine()
创建 DataFrame
wine_df = pd.DataFrame(data=np.c_[wine_data['data'], wine_data['target']],
columns=wine_data['feature_names'] ['target'])
显示数据集的前几行
wine_df.head()
```
步骤 3: 数据集概览
让我们看一下数据集的基本信息:
```python
查看数据集的形状
print("数据集形状:", wine_df.shape)
查看列名
print("\n列名:", wine_df.columns)
查看数据类型
print("\n数据类型信息:")
print(wine_df.info())
查看数据的统计摘要
print("\n数据统计摘要:")
print(wine_df.describe())
```
通过这些步骤,你可以成功导入 Wine 红酒数据集,并且对数据集有了一定的了解。你可以进一步探索数据,进行可视化和分析,或者将其用于机器学习模型的训练。
免责声明:本网站部分内容由用户自行上传,若侵犯了您的权益,请联系我们处理,谢谢!